Nos Bastidores: Melhorando a Infraestrutura do Repositório
This blog site has been archived. Go to react.dev/blog to see the recent posts.
Enquanto trabalhávamos no React 16, reformulamos a estrutura de pastas e muito do ferramental de construção no repositório React. Entre outras coisas, introduzimos projetos como Rollup, Prettier, e Google Closure Compiler em nosso fluxo de trabalho. As pessoas frequentemente nos fazem perguntas sobre como usamos essas ferramentas. Neste post, nós gostaríamos de compartilhar algumas das alterações que fizemos em nossa infraestrura de build e teste em 2017 e o que as motivou.
Enquanto essas mudanças nos ajudaram a fazer o React melhor, elas não afetam a maioria do usuários React diretamente. Contudo, esperamos que os posts sobre eles possam ajudar outros autores de bibliotecas a resolver problemas semelhantes. Nossos colaboradores também podem achar essas anotações úteis!
Formatando Código com Prettier
O React foi um dos primeiros grandes repositórios a adotar completamente formatação automática de código opinativo com Prettier. Nossa configuração atual do Prettier consiste em:
- Um script local
yarn prettierque usa a API Node do Prettier para formatar arquivos no lugar. Normalmente, executamos isso antes de confirmar alterações. É rápido porque só verifica o arquivo alterado desde que esteja divergente com a branch master remota. - O script que roda o Prettier como parte dos nossos checks de integração contínua. Não tentará sobrescrever os arquivos, mas, em vez disso, falhará a compilação se algum arquivo for diferente da saída Prettier desse arquivo. Isso garante que não possamos mergear um pull request, a menos que ela tenha sido totalmente formatado.
Alguns membros da equipe também configuraram integrações com o editor. Nossa experiência com o Prettier tem sido fantástica e recomendamos a qualquer equipe que utilize JavaScript.
Reestruturando o Monorepo
Desde que o React foi dividido em pacotes, tem sido um monorepo: um conjunto de pacotes sob o guarda-chuva de um único repositório. Isso facilitou a coordenação de alterações e o compartilhamento das ferramentas, mas nossa estrutura de pastas estava profundamente aninhada e difícil de entender. Não ficou claro quais arquivos pertenciam a qual pacote. Depois de liberar o React 16, decidimos reorganizar completamente a estrutura do repositório. Aqui está como nós fizemos isso.
Migrating to Yarn Workspaces
O gerenciador de pacote Yarn introduziu um recurso chamado Workspaces há alguns meses atrás. Esse recurso permite que você diga ao Yarn onde os pacotes do seu monorepo estão localizados na árvore de fontes. Toda vez que você roda yarn, além de instalar suas dependências, ele também configura os links simbólicos que apontam a partir do node_modules do seu projeto, para as pastas de origem dos seus pacotes.
Graças aos Workspaces, importações absolutas entre os nossos próprios pacotes (como importar react do react-dom) “simplismente funcionam” com todas as ferramentas que suportam o mecanismo de resolução do Node. O único problema que encontramos foi no Jest não executando as transformações dentro dos pacotes vinculados, mas nós encontramos uma correção, e foi mergeado dentro do Jest.
Para habilitar o Yarn Workspaces, nós adicionamos "workspaces": ["packages/*"] para nosso package.json, e movemos todo código dentro do top-level packages/* folders, cada um com o seu próprio arquivo package.json.
Cada pacote é estruturado de forma semelhante. Para cada ponto de entrada da API pública, como react-dom ou react-dom/server, existe um arquivo na pasta raiz do pacote que reexporta a implementação do /src/ subpasta. A decisão de apontar pontos de entrada para a fonte e não para as versões construídas foi intencional. Tipicamente, nós executamos novamente um subconjunto de testes após cada alteração durante o desenvolvimento. Ter que construir o projeto para executar um teste teria sido proibitivamente lento. Quando publicamos pacotes para o npm, substituímos esses pontos de entrada por arquivos na pasta /npm/ que apontam para os artefatos da build.
Nem todos os pacotes precisam ser publicados no npm. Por exemplo, mantemos alguns utilitários que são pequenos o suficiente e podem ser duplicados com segurança em um pseudo-pacote chamado shared. Nosso bundler está configurado para apenas tratar dependências declaradas no package.json como externas por isso, felizmente empacota o código do shared dentro do react e react-dom sem deixar nenhuma referências a shared/ nos artefatos de build. Então você pode usar Yarn Workspaces mesmo que você não planeje publicar pacotes npm!
Removendo o sistema de módulo personalizado
No passado, usamos um sistema de módulo não padronizado chamado “Haste” que permite importar qualquer arquivo de qualquer outro arquivo por sua única @providesModule diretiva, não importa onde esteja na árvore. Ele evita o problema de importações relativas profundas com caminhos como ../../../../ e é ótimo para o código do produto. Entretanto, isso dificulta entender as dependências entre pacotes. Nós também tivemos que recorrer a hacks para fazê-lo funcionar com diferentes ferramentas.
Nós decidimos remover o Haste e usar ao invés, a resolução Node com importações relativas. Para evitar o problema dos caminhos relativos profundos, nós temos achatado nossa estrutura de respositório de modo que vá no máximo um nível no fundo de cada pacote:
|-react
| |-npm
| |-src
|-react-dom
| |-npm
| |-src
| | |-client
| | |-events
| | |-server
| | |-sharedNeste caminho, os caminhos relativos só podem ter um ./ ou ../ seguido pelo nome do arquivo. Se um pacote precisa importar algo de outro pacote, pode fazê-lo com uma importação absoluta no nível superior do ponto de entrada.
Na prática, nós ainda temos algumas importações “internas” cross-package que violam este princípio, mas são explícitas e planejamos gradualmente nos livrar delas.
Compilando Pacotes Simples
Historicamente, o React era distribuído em dois diferentes formatos: como uma compilação de arquivo único que você pode adicionar com uma tag <script> no navegador, e como uma coleção de CommonJS módulos que você pode empacotar como uma ferramenta como webpack ou Browserify.
Antes do React 16, cada arquivo fonte React tinha um módulo CommonJS correspondente que foi publicado como parte de um pacote npm. Importando react ou react-dom empacotadores conduzidos para o ponto de entrada do pacote a partir do qual eles iriam construir uma árvore de dependência com os módulos CommonJS na pasta interna lib.
Entretanto, esta abordagem teve várias desvantagens:
- Era inconsistente. Diferentes ferramentas produzem pacotes de tamanhos diferentes para código idêntico importando o React, com a diferença indo até 30 kB (antes do gzip).
- Era ineficiente para usuários de empacotadores. O código produzido pela maioria dos empacotadores hoje, possuem muitos “código de cola” nos limites do módulo. Mantém os módulos isolados uns dos outros, mas aumenta o tempo de parse, o tamanho do bundle, e o tempo de build.
- Era ineficiente para usuários de Node. Ao rodar em Node, com
process.env.NODE_ENVverifica se antes apenas em tempo de desenvolvimento, o código incorre na sobrecarga de realmente procurar variáveis de ambiente. Isto desacelerou a renderização do React no servidor. Não foi possível armazenar em cache em uma variável porque impediu a eliminação do código morto com Uglify. - Quebrou o encapsulamento. React internals foram expostos tanto no open source (como
react-dom/lib/*imports) e internamente no Facebook. Foi conveniente a princípio como uma maneira de compartilhar utilitários entre projetos, mas com o tempo tornou-se um fardo de manutenção porque renomear ou alterar os tipos de argumento de funções internas iria quebrar projetos não relacionados. - Isso impediu a experimentação. Não havia como o time do React experimentar com qualquer técnica avançada de compilação. Por exemplo, na teoria, poderíamos poder aplicar o Google Closure Compiler Advanced otimizações ou Prepack para alguns dos nossos códigos, mas eles são projetados para trabalhar em pacotes completos ao invés de pequenos módulos individuais que usamos para enviar para o npm.
Devido a estas e outras questões, nós mudamos nossa estratégia no React 16. Nós ainda enviamos módulos CommonJS para Node.js e empacotadores, mas em vez de publicar muitos arquivos individuais no pacote npm, nós publicamos apenas dois bundles CommonJS por ponto de entrada.
Por exemplo, quando você importa o react com React 16, o empacotador encontra o ponto de entrada que apenas reexporta um dos dois arquivos:
'use strict';
if (process.env.NODE_ENV === 'production') {
module.exports = require('./cjs/react.production.min.js');
} else {
module.exports = require('./cjs/react.development.js');
}Em todos os pacotes fornecidos pelo React, a pasta cjs (abreviatura de “CommonJS”) contém um pacote pré-construído de desenvolvimento e um de produção para cada ponto de entrada.
Por exemplo, react.development.js é a versão destinada ao desenvolvimento. É legível e inclui comentários. Por outro lado, react.production.min.js foi reduzido e otimizado antes de ser publicado no npm.
Observe como essa é essencialmente a mesma estratégia que usamos para as compilações de navegador de arquivo único (que agora residem no diretório umd, abreviatura para Universal Module Definition). Agora apenas aplicamos a mesma estratégia ao CommonJS builds também.
Migrando para o Rollup
Apenas compilando módulos CommonJS em pacotes de arquivos únivos não resolve todos os problemas acima. As vitórias realmente significativas vieram de migrando nosso sistema de build do Browserify para Rollup.
O Rollup foi projetado com bibliotecas em vez de aplicativos em mente, e isso é um ajuste perfeito para o caso de uso do React. Isso resolve bem um problema: como combinar múltiplos módulos em um arquivo simples com o mínimo de código lixo no meio. Para alcançar isso, em vez de transformar módulos em funções assim como muitos outros empacotadores, coloca-se todo o código no mesmo escopo, e renomeia-se as variáveis para que não entrem em conflito. Isso produz código que é mais fácil para a engine do Javascript analisar, para um ser humano ler, e para um minificador otimizar.
O Rollup atualmente não suporta alguns recursos que são importantes para builders de aplicações, como code splitting. No entanto, não visa substituir ferramentas como o webpack que faz um ótimo trabalho nisso.
Você pode encontrar nossa configuração de build do Rollup aqui, com uma lista de plugins que utilizamos atualmente.
Migrando para o compilador do Google Closure
Depois de migrar para pacotes planos, nós começamos a usar a versão JavaScript do compilador Google Closure nesse modo “simples”. Em nossa experiência, mesmo com as otimizações avançadas desativadas, ainda fornecia uma vantagem significativa sobre o Uglify, pois foi capaz de eliminar melhor códigos mortos e automaticamente pequenas funções embutidas quando apropriado.
No início, nós poderíamos apenas utilizar o compilador do Google Closure para os pacotes React que nós enviamos em código aberto. No Facebook, nós ainda precisávamos que os pacotes de check-in não fossem minificados para que pudéssemos simbolizar quebras do React em produção com nossas ferramentas de relatórios de erros. Nós acabamos contribuindo uma flag que desabilita completamente o passo de renomeação do compilador. Isso nos permite aplicar outras otimizações como funções embutidas, mas mantém o código totalmente legível para as compilações Facebook-specific do React. Para melhorar a legibilidade do output, nós também formatamos esse build customizado usando Prettier. Curiosamente, executar o Prettier nos pacotes de produção enquanto depura o processo de compilação é uma ótima maneira de encontrar código desnecessário nos pacotes!
Atualmente, todos os pacotes de produção do React rodam através do compilador do Google Closure em um modo simples, e nós podemos considerar a habilitação de otimizações avançadas no futuro.
Proteção Contra a Eliminação de Códigos Mortos Fracos
Enquanto nós utilizamos uma solução eficiente de eliminação de códigos mortos no React em si, não podemos fazer muitas suposições sobre as ferramentas utilizadas pelos consumidores do React.
Tipicamente, quando você configura um pacote para produção , você precisa informá-lo para substituir process.env.NODE_ENV com a string literal de "production". Esse processo às vezes é chamado de “envification”. Considere esse código:
if (process.env.NODE_ENV !== "production") {
// development-only code
}Depois do processo de envification, essa condição sempre será false, e pode ser completamente eliminado pela maioria dos minificadores:
if ("production" !== "production") {
// development-only code
}Entretanto, se o pacote estiver configurado incorretamente, você pode acidentalmente enviar código de desenvolvimento para produção. Nós não podemos prevenir isso completamente, mas nós tomamos algumas medidas para mitigar os casos comuns quando isso acontece.
Protegendo Contra a Envificação Tardia
Como mencionado acima, nossos pontos de entrada agora se parecem com isso:
'use strict';
if (process.env.NODE_ENV === 'production') {
module.exports = require('./cjs/react.production.min.js');
} else {
module.exports = require('./cjs/react.development.js');
}Entretanto, alguns processos de empacotadores requerem antes uma envificação. Nesse caso, mesmo se o bloco else nunca executa, o arquivo cjs/react.development.js ainda é empacotado.
Para prevenir isso, nós também embrulhamos todo o conteúdo do pacote de desenvolvimento em outra verificação process.env.NODE_ENV dentro de cjs/react.development.js no pacote em si:
'use strict';
if (process.env.NODE_ENV !== "production") {
(function() {
// bundle code
})();
}Dessa forma, mesmo que o pacote da aplicação inclua ambas as versões de desenvolvimento e de produção do arquivo, a versão do desenvolvimento estará vazia após a envificação.
O wrapper adicional IIFE é necessário porque algumas declarações (e.g. funções) não podem ser colocadas dentro de uma declaração if em JavaScript.
Detectando Eliminação de Código Morto Desconfigurada
Apesar de a situação esteja mudando, muitos empacotadores populares ainda não forçam os usuários a especificar o modo de desenvolvimento ou modo de produção. Nesse caso process.env.NODE_ENV é tipicamente fornecido por um polyfill de tempo de execução, mas a eliminação do código morto não funciona.
Não podemos prevenir completamente os usuários do React a configurarem incorretamente seus empacotadores, mas introduzimos algumas verificações adicionais para isso no React DevTools.
Se o pacote de desenvolvimento for executado, React DOM reporta isso para o React DevTools:

Há também mais um cenário ruim. Algumas vezes, process.env.NODE_ENV é setado para "production" em tempo de execução em vez de no tempo de build. É assim que deve funcionar no Node.js, mas isso é ruim para os builds do lado do client porque o código de desenvolvimento desnecessário é empacotado apesar de nunca ser executado. Isso é mais difícil de detectar mas encontramos uma heurística que funciona bem na maioria dos casos e não parece produzir falsos positivos.
Podemos escrever uma função que contenha uma branch apenas de desenvolvimento com uma string literal arbitrária. Então, se process.env.NODE_ENV é setado para "production", podemos chamar toString() nessa função e verificar que a string literal na branch de apenas desenvolvimento foi retirada. Se ainda estiver lá, a eliminação do código morto não funcionou, e precisamos avisar o desenvolvedor. Desde que os desenvolvedores podem não notar os avisos do React DevTools em um website de produção, nós também lançamos um erro dentro de setTimeout do React DevTools na esperança de que seja captado pela análise de erros.
Reconhecemos que essa abordagem é um tanto frágil. O método toString() não é confiável e pode mudar seu comportamento em futuras versões do navegador. É por isso que colocamos essa lógica no próprio React DevTools em vez de no React. Isso nos permite removê-lo posteriormente, caso se torne problemático. Também avisamos apenas se encontramos a string literal especial, e não se não a encontramos. Desta forma, se a saída toString() se tornar opaca, ou for substituída, o aviso simplesmente não disparará.
Perceber erros antecipadamente
Queremos detectar bugs o mais cedo possível. No entanto, mesmo com nossa ampla cobertura de teste, ocasionalmente cometemos um erro crasso. Fizemos várias alterações em nossa infraestrutura de construção e teste este ano para torná-la mais difícil de bagunçar.
Migrando para os ES Modules
Com CommonJS require() e module.exports, é fácil importar uma função que realmente não existe e não perceber isso até que você a chame. No entanto, ferramentas como Rollup, que oferecem suporte nativo à sintaxe de import e export falham o build se você digitar incorretamente uma importação nomeada. Após lançar o React 16, nós convertemos todo o código-fonte do React para a sintaxe do ES Modules.
Isso não apenas forneceu alguma proteção extra, mas também ajudou a melhorar o tamanho da construção. Muitos módulos React exportam apenas funções utilitárias, mas o CommonJS nos forçou a agrupá-los em um objeto. Transformando essas funções utilitárias em exportações nomeadas e eliminando os objetos que as continham, permitimos que o Rollup as coloque no escopo de nível superior e, assim, deixamos o minificador alterar seus nomes nas compilações de produção.
Por enquanto, decidimos converter apenas o código-fonte para ES Modules, mas não os testes. Usamos utilitários poderosos como jest.resetModules() e queremos manter um controle mais rígido sobre quando os módulos são inicializados nos testes. Para consumir os ES Modules de nossos testes, habilitamos o Babel CommonJS transform, mas apenas para o ambiente de teste.
Executando testes no modo de produção
Historicamente, executamos todos os testes em um ambiente de desenvolvimento. Isso nos permitiu confirmar sobre as mensagens de advertência produzidas pelo React e parecia fazer sentido geral. No entanto, embora tentemos manter as diferenças entre os caminhos do código de desenvolvimento e produção, ocasionalmente cometeríamos um erro em branches de código somente de produção que não foram cobertos pelos testes e causaríamos um problema no Facebook.
Para resolver esse problema, nós adicionamos um novo script yarn test-prod que é executado em CI para cada pull request, e executa todos os casos de teste do React em modo de produção. Envelopamos todas as confirmações sobre mensagens de aviso em blocos condicionais somente de desenvolvimento em todos os testes, para que eles ainda possam verificar o restante do comportamento esperado em ambos os ambientes. Uma vez que temos um Babel transform personalizado que substitui as mensagens de erro de produção com os error codes, nós também adicionamos uma transformação reversa como parte da execução do teste de produção.
Usando API pública em testes
Quando nós estávamos rescrevendo o React reconcilier, reconhecemos a importância de escrever testes na API pública, em vez de módulos internos. Se o teste for escrito na API pública, fica claro o que está sendo testado da perspectiva do usuário e você pode executá-lo mesmo se reescrever a implementação do zero.
Entramos em contato com a maravilhosa comunidade do React pedindo ajuda para converter os testes restantes para usar a API pública. Quase todos os testes estão convertidos agora! O processo não foi fácil. Às vezes, um teste unitário apenas chama um método interno e é difícil descobrir o que o comportamento observável do ponto de vista do usuário deveria ser testado. Encontramos algumas estratégias que ajudaram nisso. A primeira coisa que tentaríamos é encontrar o histórico do git de quando o teste foi adicionado e encontrar pistas no problema e na descrição do pull request. Frequentemente, eles conteriam casos de reprodução que acabaram sendo mais valiosos do que os testes unitários originais! Uma boa maneira de verificar a suposição é tentar comentar linhas individuais no código-fonte que está sendo testado. Se o teste falhar, sabemos com certeza que ele estressa o caminho do código fornecido.
Gostaríamos de agradecer profundamente a todos que contribuíram para este esforço.
Executando testes em bundles compilados
Há também mais um benefício em escrever testes na API pública: agora podemos executá-los nos bundles compilados.
Isso nos ajuda a garantir que ferramentas como Babel, Rollup e Google Closure Compiler não introduzam regressões. Isso também abre a porta para futuras otimizações mais agressivas, pois podemos ter certeza de que o React ainda se comportará exatamente como esperado depois delas.
Para implementar isso, nós criamos uma segunda configuração no Jest. Ela sobrescreve nossa configuração inicial mas aponta react, react-dom, e outros pontos de entrada para a pasta /build/packages/. Essa pasta não contém qualquer código fonte do React, e reflete o que é publicado no npm. Ela é preenchida após a execução do yarn build.
Isso nos permite executar exatamente os mesmos testes que normalmente executamos na source, mas os executa usando bundles do React pré-construídos de desenvolvimento e produção produzidos com Rollup e Google Closure Compiler.
Ao contrário da execução de teste normal, a execução de teste de pacote depende dos produtos de build, portanto, não é excelente para iteração rápida. No entanto, ela ainda é executada no servidor de CI, portanto, se algo quebrar, o teste será exibido como falho e saberemos que não é seguro executar o merge com a main.
Ainda existem alguns arquivos de teste que intencionalmente não executamos nos pacotes. Às vezes, nós queremos contruir um mock de um módulo interno ou substituir uma feature flag que ainda não foi exposta ao público. Para esses casos, colocamos um arquivo de teste na lista negra, renomeando-o de MyModule-test.js paraMyModule-test.internal.js.
Atualmente, mais de 93% dos 2.650 testes React são executados nos pacotes compilados
Utilizando Lint nos Pacotes Compilados
Além de utilizar o lint no nosso código-fonte, executamos um conjunto muito mais limitado de regras linting (de fato, apenas duas delas) nos pacotes compilados. Isso nos dá uma camada extra de proteção contra regressões nas ferramentas subjacentes e garante que os pacotes não usem nenhum recurso de linguagem que não seja compatível com navegadores mais antigos.
Simulando a Publicação de Pacotes
Mesmo rodar os testes nos pacotes buildados não é suficiente para evitar o envio de uma atualização quebrada. Por exemplo, usamos o campo files em nossos arquivospackage.json para especificar uma lista de permissões de pastas e arquivos que devem ser publicados no npm. No entanto, é fácil adicionar um ponto de entrada a um pacote, mas esqueça de adicioná-lo à lista de permissões. Mesmo os testes de pacote seriam aprovados, mas após a publicação, o novo ponto de entrada estaria faltando.
Para evitar situações como essa, agora estamos simulando a publicação do npm, executando npm pack e imediatamente descompactando o arquivo depois do build. Assim como o npm publish, este comando filtra qualquer coisa que não esteja na lista branca de files. Com essa abordagem, se esquecêssemos de adicionar um ponto de entrada à lista, ele estaria faltando na pasta de construção e os testes de pacote que dependem dele falhariam.
Criando Ferramentas de Teste Manual
Nossos testes unitários são executados apenas no ambiente Node, mas não nos navegadores. Esta foi uma decisão intencional porque as ferramentas de teste baseadas em navegador eram instáveis em nossa experiência e não detectaram muitos problemas de qualquer maneira.
Poderíamos nos safar com isso porque o código que toca o DOM é consolidado em alguns arquivos e não muda com tanta frequência. Todas as semanas, atualizamos a base de código do Facebook.com para o último commit do React no master. No Facebook, usamos um conjunto interno de testes do WebDriver para fluxos de trabalho de produtos críticos, e estes capturam algumas regressões. As atualizações do React são entregues primeiro aos funcionários, então bugs graves são relatados imediatamente antes de atingirem dois bilhões de usuários.
Ainda assim, era difícil revisar as alterações relacionadas ao DOM e, ocasionalmente, cometíamos erros. Em particular, era difícil lembrar todos os casos extremos que o código teve que tratar, por que eles foram adicionados e quando era seguro removê-los. Nós consideramos adicionar alguns testes automatizados que são executados no navegador, mas não queríamos diminuir o ciclo de desenvolvimento e lidar com um CI frágil. Além disso, os testes automatizados nem sempre detectam problemas de DOM. Por exemplo, um valor de entrada exibido pelo navegador pode não corresponder ao que relata como uma propriedade DOM.
Nós conversamos sobre isso com Brandon Dail, Jason Quense, e Nathan Hunzaker. Eles estavam enviando patches substanciais para o React DOM, mas ficaram frustrados porque não os revisamos oportunamente. Decidimos dar a eles acesso de commit, mas pedimos que criassem um conjunto de testes manuais para áreas relacionadas ao DOM, como gerenciamento de entrada. O conjunto inicial de ferramentas manuais continuou crescendo durante o ano.
Esses acessórios são implementados como um aplicativo React localizado em fixtures / dom. Adicionar um acessório envolve escrever um componente React com uma descrição do comportamento esperado e links para os problemas apropriados e peculiaridades do navegador, como neste exemplo:

O aplicativo de fixture permite que você escolha uma versão do React (local ou uma das versões publicadas) que é útil para comparar o comportamento antes e depois das alterações. Quando mudamos o comportamento relacionado à forma como interagimos com o DOM, podemos verificar que ele não regrediu, passando pelos acessórios relacionados em diferentes navegadores.
Em alguns casos, uma mudança provou ser tão complexa que exigiu um acessório autônomo feito sob medida para verificá-la. Por exemplo, a manipulação de atributos DOM foi muito difícil começar com confiança no início. Continuamos descobrindo diferentes casos extremos e quase desistimos de fazer isso a tempo para o lançamento do React 16. No entanto, construímos uma ferramenta de “tabela de atributos” que renderiza todos os atributos suportados e seus erros ortográficos com a versão anterior e a próxima do React, e exibe as diferenças. Demorou algumas iterações (o insight principal foi agrupar atributos com comportamento semelhante), mas acabou nos permitindo corrigir todos os principais problemas em apenas alguns dias.
Analisamos a tabela para examinar o novo comportamento para cada caso (e descobrimos alguns bugs antigos também) pic.twitter.com/cmF2qnK9Q9
— Dan Abramov (@dan_abramov) September 8, 2017
Examinar os acessórios ainda dá muito trabalho e estamos considerando automatizar parte disso. Ainda assim, o aplicativo de fixture é inestimável até mesmo como documentação para o comportamento existente e todos os casos extremos e bugs do navegador que o React lida atualmente. Isso nos dá confiança para fazer alterações significativas na lógica sem quebrar casos de uso importantes. Outra melhoria que estamos considerando é criar um bot do GitHub e implantar os fixtures automaticamente para cada pull request que toque nos arquivos relevantes para que qualquer pessoa possa ajudar no teste do navegador.
Prevenindo Loops Infinitos
A base de código React 16 contém muitos laços while. Eles nos permitem evitar os temidos deep stack traces que ocorriam com versões anteriores do React, mas podem tornar o desenvolvimento do React realmente difícil. Sempre que há um erro em uma condição de saída, nossos testes simplesmente travam e demoramos um pouco para descobrir qual dos loops está causando o problema.
Inspirado pela estratégia adotada pelo Repl.it, nós adicionamos um plugin Babel que previne loops infinitos no ambiente de teste. Se algum loop continuar por mais do que o número máximo permitido de iterações, lançamos um erro e o reprovamos imediatamente para que Jest possa mostrar onde exatamente isso aconteceu.
Essa abordagem tem uma armadilha. Se um erro lançado pelo plugin Babel for detectado e ignorado na pilha de chamadas, o teste será aprovado, embora tenha um loop infinito. Isso é muito, muito ruim. Para resolver este problema, nós definimos um campo global antes de lançar o erro. Então, após cada execução de teste, nós relançamos esse erro se o campo global tiver sido definido. Desta forma, qualquer loop infinito causará uma falha no teste, não importando se o erro do plugin Babel foi detectado ou não.
Customizando o Build
Houve algumas coisas que tivemos que ajustar depois de apresentar nosso novo processo de construção. Demorou um pouco para descobri-los, mas estamos moderadamente felizes com as soluções a que chegamos.
Eliminação de código morto
A combinação de Rollup e Google Closure Compiler já nos leva muito longe em termos de remoção de código somente de desenvolvimento em pacotes de produção. Nós substituímos o literal __DEV__ com uma constante booleana durante a compilação, e tanto o Rollup quanto o Google Closure Compiler, juntos, podem remover os ramos de código if (false) {} e até mesmo alguns padrões mais sofisticados. No entanto, há um caso particularmente desagradável:
import warning from 'fbjs/lib/warning';
if (__DEV__) {
warning(false, 'Blimey!');
}Esse padrão é muito comum no código-fonte do React. No entanto, fbjs / lib / warning é uma importação externa que não está sendo empacotada pelo Rollup para o pacote do CommonJS. Portanto, mesmo se a chamada warning () acabar sendo removida, Rollup não sabe se é seguro remover para a própria importação. E se o módulo tiver um efeito colateral durante a inicialização? Então, removê-lo não seria seguro.
Para resolver este problema, usamos a opção treeshake.pureExternalModules do Rollup que usa uma série de módulos que podemos garantir que não têm efeitos colaterais. Isso permite que o Rollup saiba que uma importação para fbjs / lib / warning é segura para remover completamente se seu valor não estiver sendo usado. No entanto, se estiver sendo usado (por exemplo, se decidirmos adicionar avisos na produção), a importação será preservada. É por isso que essa abordagem é mais segura do que substituir módulos por calços vazios.
Quando otimizamos algo, precisamos garantir que não regrida no futuro. E se alguém introduzir uma nova importação somente de desenvolvimento de um módulo externo e não perceber que também precisa adicioná-lo a pureExternalModules? O Rollup imprime um aviso em tais casos, mas nós decidimos reprovar completamente a compilação em vez disso. Isso força a pessoa a adicionar uma nova importação externa somente de desenvolvimento para especificar explicitamente se tem efeitos colaterais ou não toda vez.
Bifurcando Módulos
Em alguns casos, pacotes diferentes precisam conter códigos ligeiramente diferentes. Por exemplo, os bundles do React Native têm um mecanismo de tratamento de erros diferente que mostra uma caixa vermelha em vez de imprimir uma mensagem no console. No entanto, pode ser muito inconveniente encadear essas diferenças em todos os módulos de chamada.
Problemas como esse geralmente são resolvidos com a configuração do tempo de execução. No entanto, às vezes é impossível: por exemplo, os pacotes do React DOM nem deveriam tentar importar os auxiliares redbox do React Native. Também é lamentável agrupar o código que nunca é usado em um ambiente específico.
Outra solução é usar injeção de dependência dinâmica. No entanto, isso geralmente produz um código difícil de entender e pode causar dependências cíclicas. Isso também desafia algumas oportunidades de otimização. Do ponto de vista do código, o ideal é apenas “redirecionar” um módulo para seus diferentes forks de pacotes específicos. Os forks têm exatamente a mesma API dos módulos originais, mas fazem algo diferente. Achamos esse modelo mental muito intuitivo e criamos um arquivo de configuração de fork que especifica como os módulos originais são mapeados para seus forks e as condições em que isso deve acontecer.
por exemplo, esta entrada de configuração de fork especifica diferentes feature flags para diferentes pacotes:
'shared/ReactFeatureFlags': (bundleType, entry) => {
switch (entry) {
case 'react-native-renderer':
return 'shared/forks/ReactFeatureFlags.native.js';
case 'react-cs-renderer':
return 'shared/forks/ReactFeatureFlags.native-cs.js';
default:
switch (bundleType) {
case FB_DEV:
case FB_PROD:
return 'shared/forks/ReactFeatureFlags.www.js';
}
}
return null;
},Durante a compilação, nosso plugin do Rollup personalizado substitui os módulos por seus forks se as condições forem correspondentes. Como os módulos originais e os forks são escritos como Módulos ES, Rollup e Google Closure Compiler podem reconhecer constantes como números ou booleanos e, assim, eliminam com eficiência o código morto para sinalizadores de recursos desabilitados. Em testes, quando necessário, usamos jest.mock() para apontar o módulo para a versão bifurcada apropriada.
Como um bônus, podemos querer verificar se os tipos de exportação dos módulos originais correspondem exatamente aos tipos de exportação dos forks. Podemos usar um truque de fluxo um pouco estranho, mas totalmente funcional para fazer isso:
import typeof * as FeatureFlagsType from 'shared/ReactFeatureFlags';
import typeof * as FeatureFlagsShimType from './ReactFeatureFlags.native';
type Check<_X, Y: _X, X: Y = _X> = null;
(null: Check<FeatureFlagsShimType, FeatureFlagsType>);Isso funciona essencialmente forçando o Flow a verificar se dois tipos podem ser atribuídos um ao outro (e, portanto, são equivalentes). Agora, se modificarmos as exportações do módulo original ou do fork sem alterar o outro arquivo, a verificação de tipo falhará. Isso pode ser um pouco bobo, mas achamos isso útil na prática.
Para concluir esta seção, é importante observar que você não pode especificar suas próprias bifurcações de módulo se consumir React do npm. Isso é intencional porque nenhum desses arquivos é uma API pública e não são cobertos pelas guarantees do semver. No entanto, você é sempre bem-vindo para construir o React do master ou até mesmo fazer um fork dele se não se importar com a instabilidade e o risco de divergência. Esperamos que este artigo ainda seja útil na documentação de uma abordagem possível para direcionar diferentes ambientes a partir de uma única biblioteca JavaScript.
Rastreando o Tamanho do Bundle
Como uma etapa final de compilação, agora registramos os tamanhos de compilação para todos os pacotes e gravá-los em um arquivo que se parece com este. Quando você executa yarn build, ele imprime uma tabela com os resultados:
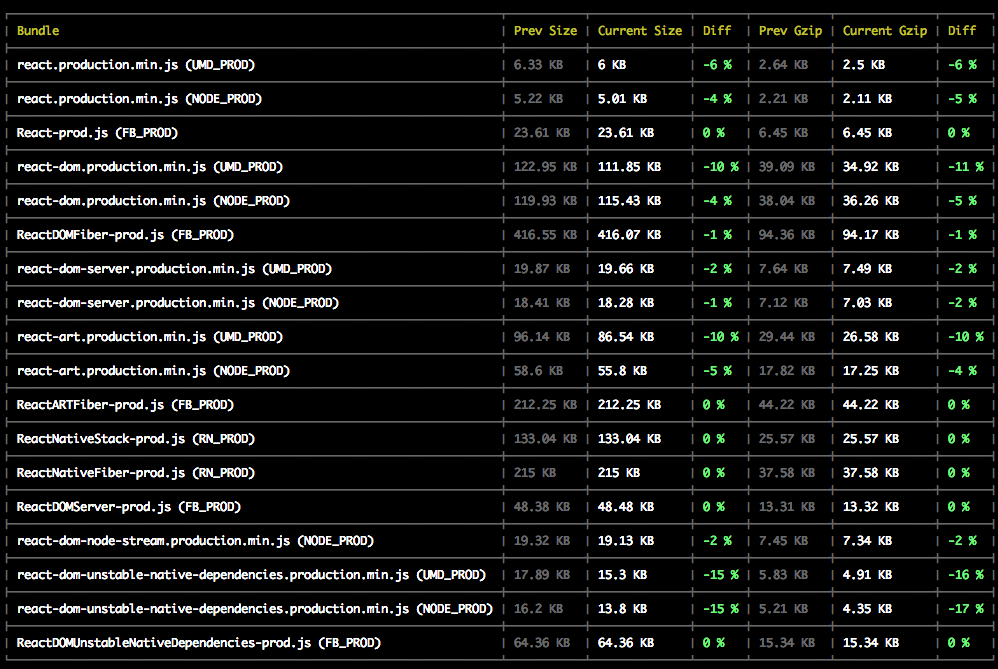
(Nem sempre parece tão bom assim. Este foi o commit que migrou o React do Uglify para o Google Closure Compiler.)
Manter os tamanhos de arquivo comprometidos para que todos vejam foi útil para rastrear alterações de tamanho e motivar as pessoas a encontrar oportunidades de otimização.
Não ficamos totalmente satisfeitos com essa estratégia porque o arquivo JSON geralmente causa conflitos de mesclagem em branches maiores. A atualização também não é obrigatória no momento, por isso fica desatualizada. No futuro, estamos considerando integrar um bot que comentaria sobre as pull requests com as mudanças de tamanho.
Simplificando o Processo de Release
Gostamos de lançar atualizações para a comunidade de código aberto com frequência. Infelizmente, o antigo processo de criação de uma versão era lento e normalmente levava um dia inteiro. Depois de algumas alterações nesse processo, agora podemos fazer uma versão completa em menos de uma hora. Aqui está o que mudamos.
Estratégia de Ramificação
A maior parte do tempo gasto no processo de lançamento antigo foi devido à nossa estratégia de ramificação. O branch main foi considerado instável e frequentemente conteria alterações significativas. Os lançamentos foram feitos a partir de um branch stable e as mudanças foram manualmente selecionadas neste branch antes de um lançamento. Nós tínhamos ferramentas para ajudar a automatizar parte desse processo, mas ainda era muito complicado de usar.
A partir da versão 16, agora lançamos do branch main. Recursos experimentais e alterações importantes são permitidos, mas devem ser ocultados atrás de feature flags para que possam ser removidos durante o processo de construção. Os novos pacotes simples e a eliminação de código morto possibilitam fazer isso sem medo de vazar código indesejado em compilações de código aberto.
Scripts Automatizados
Depois de mudar para uma main estável, criamos uma nova lista de verificação do processo de lançamento. Embora muito mais simples do que o processo anterior, isso ainda envolvia dezenas de etapas e o esquecimento de uma delas poderia resultar em uma versão interrompida.
Para resolver isso, criamos um novo processo de lançamento automatizado isso é muito mais fácil de usar e tem várias verificações integradas para garantir o lançamento de uma versão funcional. O novo processo é dividido em duas etapas: build e publish. Esta é a aparência da primeira vez que você o executa:
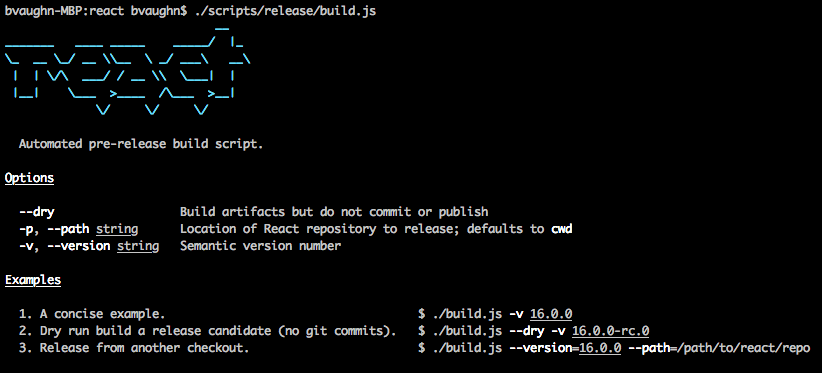
A etapa build faz a maior parte do trabalho - verificar as permissões, executar testes e verificar o status do CI. Assim que terminar, ele imprime um lembrete para atualizar o CHANGELOG e verificar o bundle usando os acessórios manuais descritos acima.
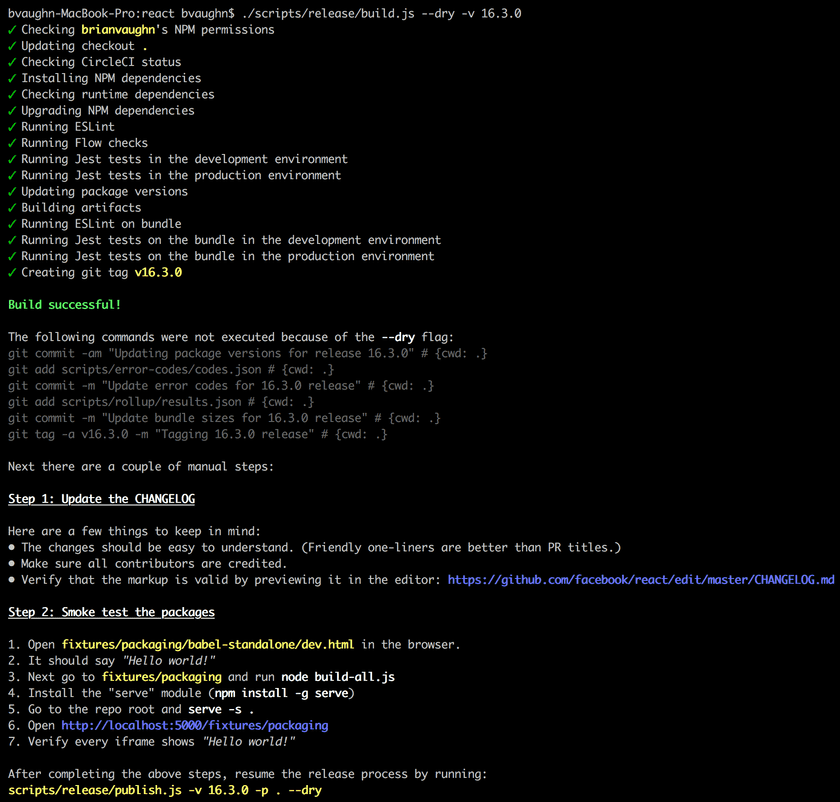
Tudo o que resta é marcar e publicar o lançamento para o NPM usando o script publish.
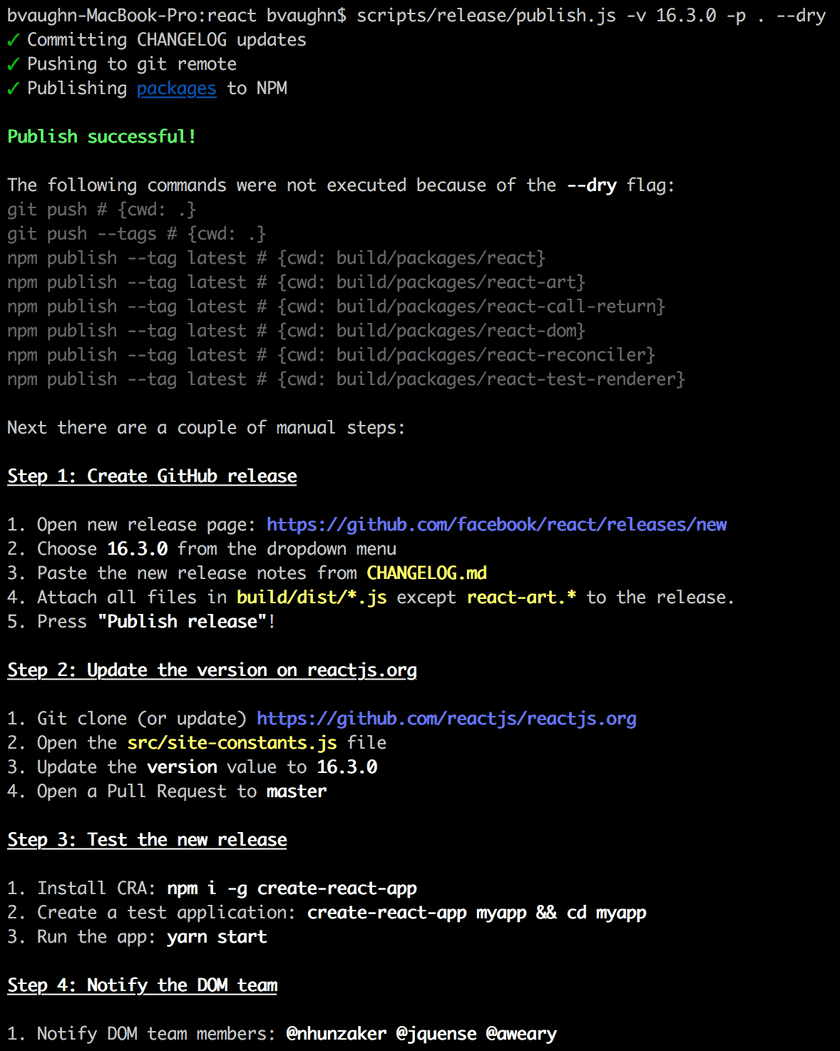
(Você deve ter notado uma flag --dry nas imagens acima. Essa flag nos permite executar uma versão, ponta a ponta, sem realmente publicar no NPM. Isso é útil ao trabalhar no próprio script de lançamento.)
Em conclusão
Esta postagem o inspirou a experimentar algumas dessas ideias em seus próprios projetos? Certamente esperamos que sim! Se você tiver outras ideias sobre como o fluxo de trabalho de construção, teste ou contribuição do React pode ser melhorado, informe-nos em nosso rastreador de issues.
Você pode encontrar as issues relacionadas pela label “build infrastructure”. Geralmente, essas são ótimas oportunidades de primeira contribuição!
Reconhecimentos
Gostaríamos de agradecer:
- Rich Harris and Lukas Taegert por manter o Rollup e nos ajudar a integrá-lo.
- Dimitris Vardoulakis, Chad Killingsworth, e Tyler Breisacher por seu trabalho no Google Closure Compiler e por conselhos oportunos.
- Adrian Carolli, Adams Au, Alex Cordeiro, Jordan Tepper, Johnson Shi, Soo Jae Hwang, Joe Lim, Yu Tian, e outros para ajudar a prototipar e implementar algumas dessas e outras melhorias.
- Anushree Subramani, Abid Uzair, Sotiris Kiritsis, Tim Jacobi, Anton Arboleda, Jeremias Menichelli, Audy Tanudjaja, Gordon Dent, Iacami Gevaerd, Lucas Lentz, Jonathan Silvestri, Mike Wilcox, Bernardo Smaniotto, Douglas Gimli, Ethan Arrowood, e outros por sua ajuda na portabilidade do conjunto de testes React para usar a API pública.